
Unlocking AI's Secrets: Everything I learned about AI
Insider Tips and Tools for Stunning Image and Video Generation


Dear friends,
over the last years I did quite a lot of experiments with AI.
Especially with AI which generates images and videos.
I want to give you a little breakdown of mostly everything I discovered.
Midjourney, Dall-E & Co.
Midjourney, Dall-E belong to the family of commercial image generation tools. They produce great and artistic images of high quality. That’s super useful for creating storyboards, testing and exploring different styles and getting lost in the rabbit hole of image generation.

I love those tools, but for me they lack a bit of the artistic freedom. They do have some visual restrictions, especially in the NSFW area. But if you want to produce high quality images, super fast, they are the way to go.
I really do wonder how the image model behind Midjourney works and how it was trained. But of course they don’t make that public…
LumaLabs, Runway & Co.
Everybody was talking about Open Ai’s Sora. The tool which can produce realistic looking AI videos with just a couple of words.
Funny enough, that tools like LumaLabs or Runway already offer this.

LumaLabs offered an App to 3D scan objects and your room, so you can generate 3D models, based on point-clouds. Now they used all their 3D data to train Ai video models. I have to say that the results are very exciting.
Runway did already offer AI video generation before which was using Stable Diffusion and some AnimateDiffusion models in the background. it was not possible to control movement properly. Now they release a very similar tool to Sora and LumaLabs. I did not test it yes, but I think it looks very promising.
Stable Diffusion
Ok, here we go. Everyone who follows my stuff, knows that I am a Stable Diffusion geek. It’s an open source software which allows to use many different AI image-models, extensions and other tools. There is a whole ecosystem around Stable Diffusion and it is super fun to explore the latest possibilities.
Automatic 1111
Automatic 1111 is the most default version of Stable Diffusion. I don’t want to go too much into detail here though. You can generate images, modify images, generate videos and much more.

Image Generation
Some long time ago I released a tutorial here which explains the basics of Stable Diffusion.

ControlNet
It is possible to use tools like ControlNet to create masks from one image and apply them to another, making precise image edits simpler and more effective.
Also this is possible for videos. So you can take a video of a dancing person and apply it on broccoli. Then you have a dancing broccoli.
Deforum
This leads us to one of my favourite tools called Deforum. With this tool it is possible to create wild animations. It always generates an image based on the previous image. This allows use to create videos which are extremely long.

It is possible to add specific prompts on specific keyframes. Like this you can say that the video starts with a lion in the jungle, but then, after 5 seconds, becomes an elephant in a desert.
Also it is possible to create camera movements in Blender and import this movement into Deforum. I made a tutorial about this here.
The only downside of Deforum is the flickering. Because it always creates one image after the other it is possible to see a jump between the frames. With tweaking on the setting it is possible to reduce it, but I never managed to completely get rid of it. Maybe in the future this will be possible.
There are some cool tool which make working with Deforum even more fun. Have a look at Parseq and Deforumation.
I could go on forever to write about Deforum, but will continue with my list now…
ComfyUI
ComfyUI is basically a node-based interface for Stable Diffusion. In Automatic 1111 we are limited to a rigid way of working, here in ComfyUI, we can build a custom workflow with many cool plugins and extensions.

With ComfyUI you can create workflows which can generate way better images like with Automatic 1111. For example you can use image-refiner plugins which improve the quality. You can run an image through several diffusion steps, you can use plugins which improve the quality of faces or add cinematic looking grain.
But one of the coolest features about ComfyUI is that it works really well with AnimateDiff. Because AnimateDiff renders the whole animation at once, and not one frame after the other like Deforum, it is possible to create very fluid looking animations.

The downside is that it is not possible to control the camera-movement or other things as intuitively as Deforum offers it. And also it is not possible to create animations which are very long. Because all the animation gets rendered at once which is pretty heavy for the GPU.
But it is so much fun to create animations with AnimateDiff. It is possible to make things dance, to morph seamlessly between images or much more. Everyday developers release custom plugins for ComfyUI and it is exciting to jump into this rabbit hole. because a rabbit hole it is…

Probably you will spend a lot of time installing custom nodes, downloading models from Huggingface, reading though forums and getting super frustrated. That’s a part of ComfyUI. Because it is such an open environment for developers and creatives, nothing really works out of the box. If you want to use ComfyUI, plan in to spend nights in front of your computer.
Stream Diffusion
Streamdiffusion is a tool which allows you to generate AI animations in realtime. I personally never used it, but some of my students in the HSBI did. You can hook it into Touch Designer and off you go.
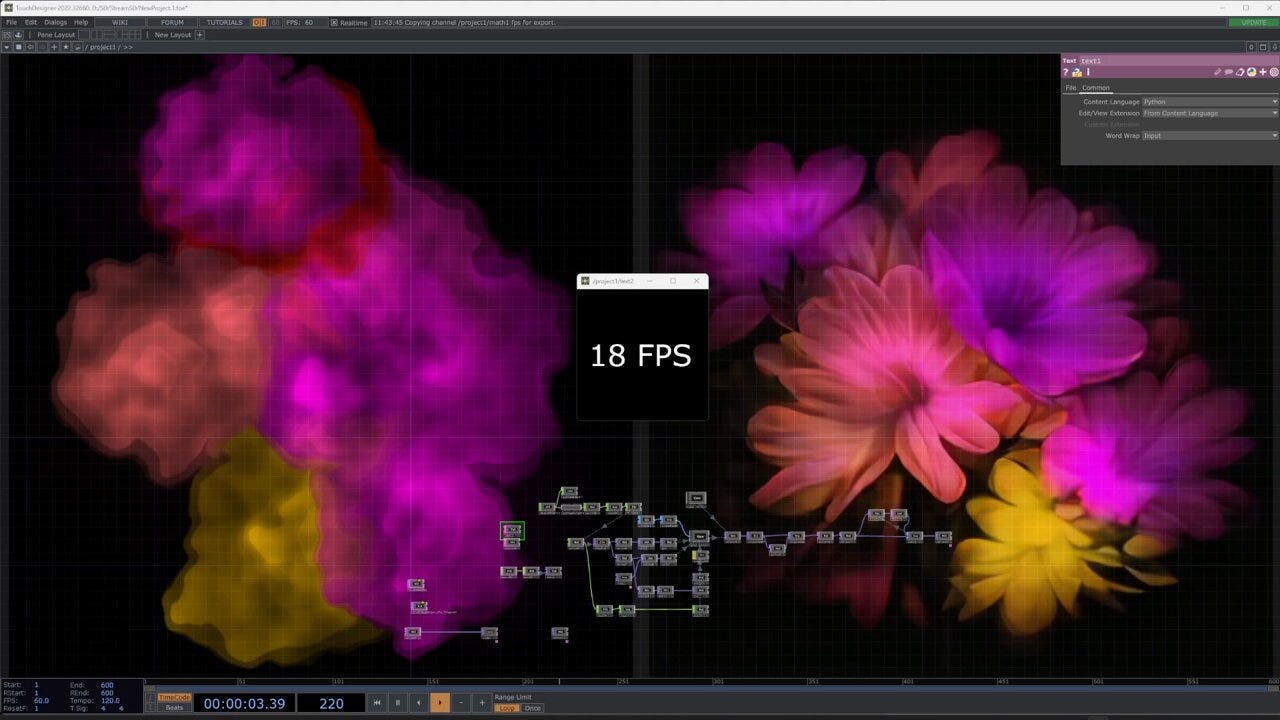
It uses the Turbo image-models which deliver a pretty good image already after one render-step.
Who is into Touch Designer, live installations and AI should definetly have a closer look at StreamDiffusion.
Online Hosting
I run all most of my AI work on my own computer. I do have a 4090 GPU which runs super fast. But also it is possible to use online-services like RunDiffusion or RunComfy.

There you pay by hour and have the Stable Diffusion tools set up for you already. This is how I did my AI experiments before I bought a good computer.
There are some other ways to run Stable Diffusion online as well and I get to that in the next paragraph.
Custom Web Interfaces
It is totally possible to code a website which talks with Stable Diffusion via API. This means that you can send prompts and settings to Stable Diffusion and you get an image or a video in return.

Image the possibilities! You can easily develop a custom tool which only generates images of pyjamas. Or you can code an artistic video-creation tool. With this actually everything is possible.
Also you can run Stable Diffusion online on a special server which is optimised for API use. Like this you don’t way by the hour like in RunDiffusion but only for the time an image gets created. Replicate offers this, but also other websites like Huggingface or Baseten (!).
Training Custom Image Models
One other cool thing to do is to train your custom image-models. Probably you want to train Loras and not checkpoints. A Lora is like a mini-image-model which can be trained on already 20 images.
There are tools like Kohya which are incredible. It is a bit complex to set up and understand, because there are so many settings. But it works. If you want to train image-models on your own computer, I recommend to look into Kohya. This tutorial here explains it pretty well.
Also I read some articles about using ComfyUI to train Loras. I tried, but was not successful.
But it is already possible to train image-models online. For example on CitivAI. For little money you can train your custom Lora and I have to say — It works pretty well. No complicated setup, just throw in the images, caption them and off you go.
Post AI
Last but not least I want to quickly talk about Post FX with AI.

There is a great tool called Topaz. It allows you to upscale videos, enhance their quality or make them slow-motion. It’s like a magic tool and it makes my life so much easier. After I generated a video with Deforum or AnimateDiff, I throw it into Topaz to improve the quality significantly.
But also you can do the opposite, print each frame and paint on top of it. Thats what we did with our latest project with ArtCamp from NY.

AI is a tool and I believe that it is still important that it is controlled by humans. Without us, AI would just generate images or videos without content or soul. It up to us to steer it, hack it and get it to do what we imagine.
Much love,
Marius